mysql
安装
- 初始化 mysqld —initialisze —console
- 记录下密码后安装 mysqld —install mysql
- 启动 net start mysql / 停止 net stop mysql
- 修改密码 alter user ‘root’@‘localhost’ identified by ‘123456’
基本使用
登录 mysql -u root -p
显示数据库show databases;
打开数据库 use mysql;
在当前库下显示其他库当中存在的表 show tables in sys;
显示表结构 desc 表名
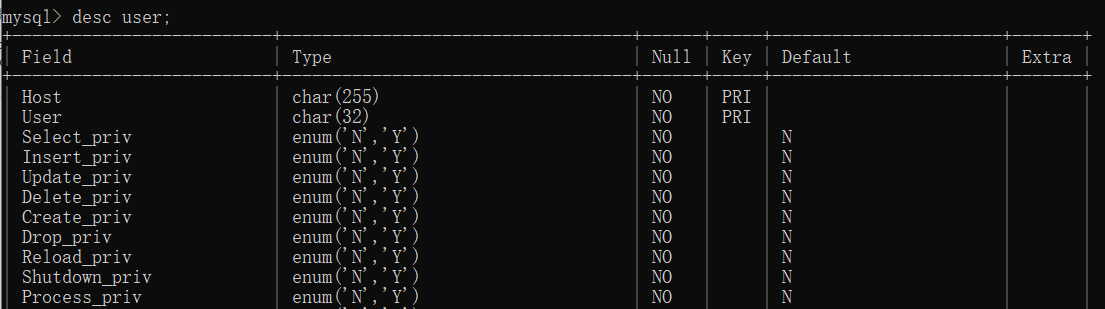 Field 属性字段
Type 数据类型,这和程序语言当中的数据类型稍微有点差别。(下面会有简单的说明)
Null 是否允许空值
Key 主键
Field 属性字段
Type 数据类型,这和程序语言当中的数据类型稍微有点差别。(下面会有简单的说明)
Null 是否允许空值
Key 主键
Default 默认值 Extra 扩展属性,例如增长的步长增量等等。例如种子是1,增量步长是2,那么值就是1 3 5 7等等。
mysql当中常用的数据类型: int 整型 float 单精度浮点,4字节 //准确表示到小数点后面6位 double 双精度浮点8字节64位。//float的两倍 char 固定长度的字符类型//如果存入的数据的实际长度比指定的长度小,自动补充空格至长度,如果实际存入数据比实际长度大,低版本采用截取策略,高版本报错。 varchar 可变长度的字符类型,可设置上限 text 文本类型 image 图片 decimal(5,2),5个数字宽度,小数点后面2位
关于整个数据库文件
Mysql支持不同的数据引擎,也就意味着不同的能力侧重面。默认的数据引擎是InnoDB。这是一种支持回卷业务的事务处理引擎,用于处理不同表类型的操作。Mysql采用热插拔式的存储引擎结构,可以实时的将需要的服务加载或者从服务中删除。可查看安装的数据库支持引擎情况。
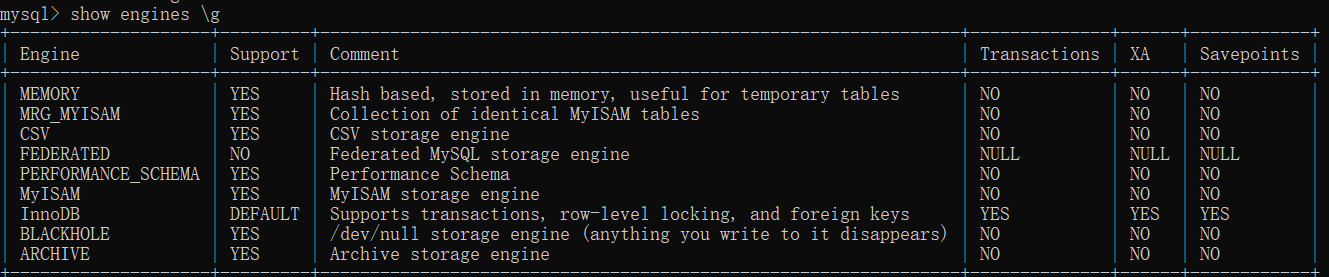 InnoDB:MySQL 8.0中的默认存储引擎。 InnoDB是用于MySQL的事务安全(兼容ACID)的存储引擎,具有提交,回滚和崩溃恢复功能来保护用户数据。 InnoDB行级锁定(无需升级为更粗粒度的锁定)和Oracle风格的一致非锁定读取可提高多用户并发性和性能。InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I / O。为了保持数据完整性, InnoDB还支持FOREIGN KEY引用完整性约束。
InnoDB:MySQL 8.0中的默认存储引擎。 InnoDB是用于MySQL的事务安全(兼容ACID)的存储引擎,具有提交,回滚和崩溃恢复功能来保护用户数据。 InnoDB行级锁定(无需升级为更粗粒度的锁定)和Oracle风格的一致非锁定读取可提高多用户并发性和性能。InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I / O。为了保持数据完整性, InnoDB还支持FOREIGN KEY引用完整性约束。
MyISAM:这些表占用的空间很小。 表级锁定 限制了读/写工作负载中的性能,因此它通常用于Web和数据仓库配置中的只读或只读工作负载中。
Memory:将所有数据存储在RAM中,以便在需要快速查找非关键数据的环境中进行快速访问。该发动机以前称为HEAP发动机。它的用例正在减少;InnoDB借助其缓冲池存储区,它提供了一种通用且持久的方式来将大多数或所有数据保留在内存中,并 NDBCLUSTER为大型分布式数据集提供了快速的键值查找。
CSV:其表实际上是带有逗号分隔值的文本文件。CSV表允许您以CSV格式导入或转储数据,以与读取和写入相同格式的脚本和应用程序交换数据。由于CSV表未建立索引,因此通常InnoDB在正常操作期间将数据保留在表中,并且仅在导入或导出阶段使用CSV表。
Archive:这些紧凑的,未索引的表旨在用于存储和检索大量很少参考的历史,存档或安全审核信息。
Blackhole:Blackhole存储引擎可以接受但不存储数据,类似于Unix /dev/null设备。查询总是返回一个空集。这些表可用于将DML语句发送到从属服务器的复制配置中,但是主服务器不会保留其自己的数据副本。
NDB(也称为 NDBCLUSTER):此集群数据库引擎特别适合于需要尽可能高的正常运行时间和可用性的应用程序。
Merge:使MySQL DBA或开发人员可以在逻辑上对一系列相同的MyISAM表进行分组并将它们作为一个对象引用。适用于VLDB环境,例如数据仓库。
Federated:提供了链接单独的MySQL服务器以从许多物理服务器创建一个逻辑数据库的能力。非常适合于分布式或数据集市环境。
Example:此引擎作为MySQL源代码中的示例,说明了如何开始编写新的存储引擎。它主要是开发人员感兴趣的。存储引擎是什么都不做的 “ 存根 ”。您可以使用此引擎创建表,但是不能将数据存储在表中或从表中检索数据。 不限于对整个服务器或架构使用相同的存储引擎,可以为任何表指定存储引擎。例如,一个应用程序可能主要使用 InnoDB表,一个CSV 表用于将数据导出到电子表格,而几个 MEMORY表用于临时工作区。
JDBC
JDBC的全称是Java数据库连接(Java Database Connectivity),它是一套用于执行SQL语句的Java API。应用程序可通过这套API连接到关系型数据库,并使用SQL语句来完成对数据库中数据的查询、新增、更新和删除等操作。
常用api
Driver接口是所有JDBC驱动程序必须实现的接口,该接口专门提供给数据库厂商使用。需要注意的是,在编写 JDBC 程序时,必须要把所使用的数据库驱动程序或类库加载到项目的classpath中(这里指MySQL驱动JAR包)。
DriverManager类用于加载JDBC驱动并且创建与数据库的连接。在DriverManager类中,定义了两个比较重要的静态方法,如表9-1所示。

Connection接口代表Java程序和数据库的连接,只有获得该连接对象后,才能访问数据库,并操作数据表。在Connection接口中定义了一系列方法,其常用方法如表9-2所示。
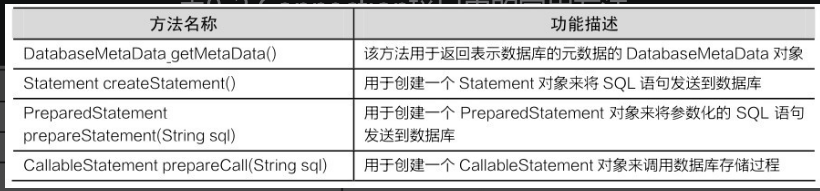
Statement接口用于执行静态的SQL语句,并返回一个结果对象。Statement接口对象可以通过Connection实例的createStatement()方法获得,该对象会把静态的SQL语句发送到数据库中编译执行,然后返回数据库的处理结果。在Statement接口中,提供了3个常用的执行SQL语句的方法,具体如表9-3所示。

Statement接口封装了JDBC执行SQL语句的方法,可以完成Java程序执行SQL语句的操作。然而在实际开发过程中往往需要将程序中的变量作为 SQL 语句的查询条件,而使用Statement接口操作这些SQL语句会过于繁琐,并且存在安全方面的问题。 针对这一问题,JDBC API 中提供了扩展的PreparedStatement接口。
PreparedStatement是Statement的子接口,用于执行预编译的SQL语句。该接口扩展了带有参数SQL语句的执行操作,应用该接口中的SQL语句可以使用占位符“?”来代替其参数,然后通过setXxx()方法为SQL语句的参数赋值。在PreparedStatement接口中提供了一些常用方法,具体如表9-4所示。
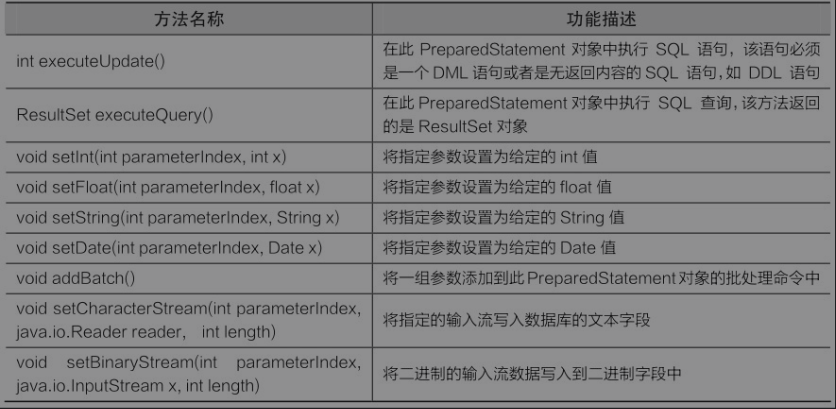
在通过setXxx()方法为SQL语句中的参数赋值时,可以通过输入参数与SQL类型相匹配的方法。例如,如果参数具有SQL类型为Integer,那么应该使用setInt()方法,也可以通过setObject()方法设置多种类型的输入参数,具体如下所示。
String sql = "INSERT INTO users(id,name,email)VALUES(?,?,?)";
PreparedStatement preStmt = conn.prepareStatement(sql);preStmt.setInt(1, 1);
//使用参数的已定义SQL类型
preStmt.setString(2, "zhangsan");
//使用参数的已定义SQL类型
preStmt.setObject(3, "zs@sina.com");
//使用setObject()方法设置参数
preStmt.executeUpdate();ResultSet接口用于保存JDBC执行查询时返回的结果集,该结果集封装在一个逻辑表格中。在ResultSet接口内部有一个指向表格数据行的游标(或指针)。ResultSet对象初始化时,游标在表格的第一行之前,调用 next()方法可将游标移动到下一行。如果下一行没有数据,则返回false。在应用程序中经常使用next()方法作为while循环的条件来迭代ResultSet结果集。ResultSet接口中的常用方法如表9-5所示。
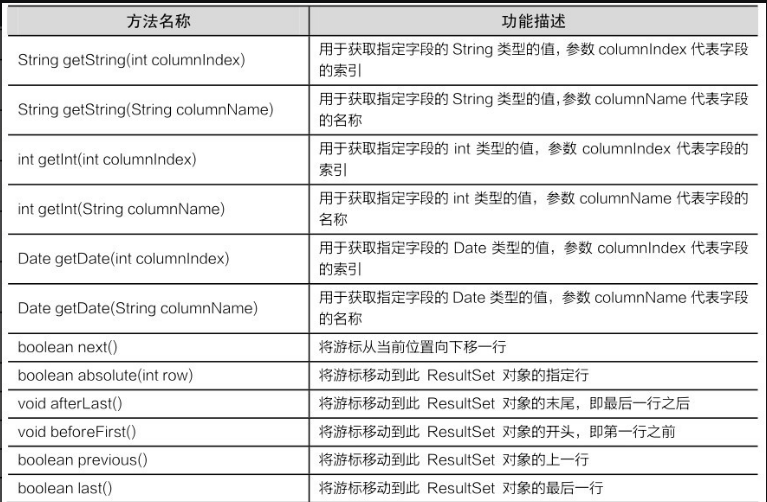 ResultSet接口中定义了大量的getXxx()方法,而采用哪种getXxx()方法取决于字段的数据类型。程序既可以通过字段的名称来获取指定数据,也可以通过字段的索引来获取指定的数据,字段的索引是从1开始编号的。例如,数据表的第一列字段名为id,字段类型为int,那么即可以使用 getInt(1)获取该列的值,也可以使用 getInt(“id”)获取该列的值。
ResultSet接口中定义了大量的getXxx()方法,而采用哪种getXxx()方法取决于字段的数据类型。程序既可以通过字段的名称来获取指定数据,也可以通过字段的索引来获取指定的数据,字段的索引是从1开始编号的。例如,数据表的第一列字段名为id,字段类型为int,那么即可以使用 getInt(1)获取该列的值,也可以使用 getInt(“id”)获取该列的值。